18. Adding Conditional Control to Text-to-Image Diffusion Models
现有的文生图模型如Stable Diffusion通常需要人工输入非常准确的提示词,而且生成的结果还是完全随机不可控制的,只能通过生成多个结果,再从中选取最佳方案。而ControlNet的提出就有效的解决了生成结果不可控的问题,通过引入更多的条件信息,例如:边缘图、深度图、法线方向图、语义分割图等,使得生成结果更接近我们的初衷。

那么如何将条件信息引入到生成模型中呢?最常见的思路可能是,直接用新的数据对原始模型进行finetune,但是我们知道SD模型是在一个超大规模的数据集(LAION-5B)上训练得到的,现有的其他的图像数据集与其相比都有着数量级的差距。因此单纯的finetune模型很容易导致过拟合、模式崩溃和灾难性遗忘的问题。为了实现使用少量的数据(几万到几百万级别)就能将新的条件信息注入到SD模型中,且能够在普通显卡平台上完成训练,作者提出了一种新的网络结构ControlNet。
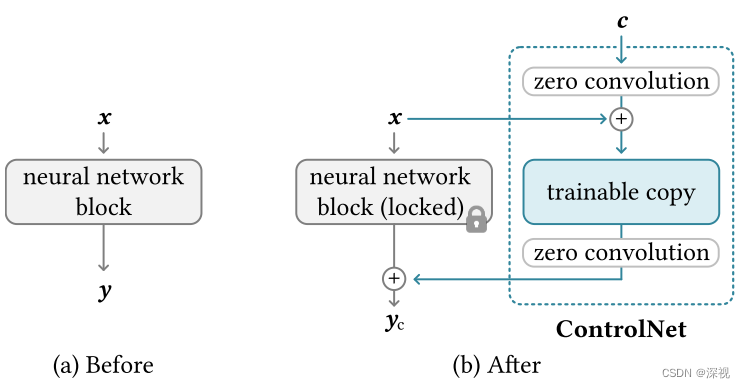
其实现方式也并不复杂,如上图所示,一个普通的神经网络块,如残差块、Transformer块,都是输入一个
x
x
x,然后给出一个输出结果
y
y
y。而ControlNet为了保证原有模型的能力不受影响,将原有模型的参数锁定,并复制得到一个可训练的模型。然后将条件输入
c
c
c经过一个“零卷积层”处理后,与原本的输入
x
x
x相加,再输入到可训练模型中。输出结果再次经过“零卷积层”并于原始输出
y
y
y相加得到最终的输出结果
y
c
y_c
yc。这里的“零卷积层”实际上就是普通的卷积层,只不过所有的权重和偏置初始化均为0。上述过程的数学化描述如下
y
c
=
F
(
x
;
Θ
)
+
Z
(
F
(
x
+
Z
(
c
;
Θ
z
1
)
;
Θ
c
)
;
Θ
z
2
)
\boldsymbol{y}_{\mathrm{c}}=\mathcal{F}(\boldsymbol{x} ; \Theta)+\mathcal{Z}\left(\mathcal{F}\left(\boldsymbol{x}+\mathcal{Z}\left(\boldsymbol{c} ; \Theta_{\mathrm{z} 1}\right) ; \Theta_{\mathrm{c}}\right) ; \Theta_{\mathrm{z} 2}\right)
yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)单纯看公式容易让人眼花,我们借助“Stable Diffusion — ControlNet 超详细讲解”这篇博客里的插图来帮助理解
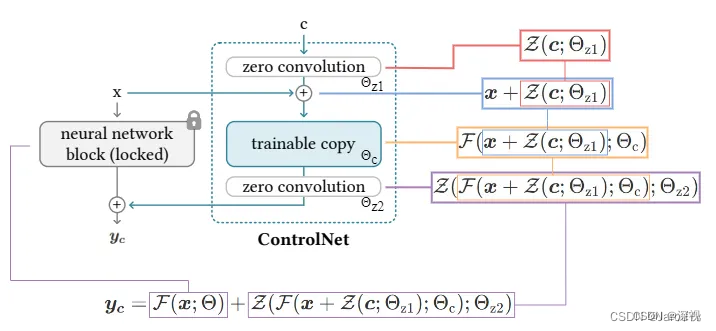
从上往下,
c
c
c是条件输入,
Θ
z
1
\Theta_{\mathrm{z}_1}
Θz1是第一个零卷积层的参数,得到卷积后的条件
Z
(
c
;
Θ
z
1
)
\mathcal{Z}\left(\boldsymbol{c} ; \Theta_{\mathrm{z} 1}\right)
Z(c;Θz1);然后与输入
x
x
x相加输入到可训练模型
F
\mathcal{F}
F中,其权重参数表示为
Θ
c
\Theta_{\mathrm{c}}
Θc;接着模型的输出再次经过权重为
Θ
z
2
\Theta_{\mathrm{z}_2}
Θz2的零卷积层,最后与原本的模型输出
y
=
F
(
x
;
Θ
)
\boldsymbol{y}=\mathcal{F}(\boldsymbol{x} ; \Theta)
y=F(x;Θ)相加得到最终的输出
y
c
\boldsymbol{y}_{\mathrm{c}}
yc。值得注意的是,由于零卷积层初始的权重参数为0,因此第一次前向计算得到的
y
c
=
y
\boldsymbol{y}_{\mathrm{c}} = \boldsymbol{y}
yc=y,随着梯度反向传播的过程,零卷积层上的权重参数也会不断更新。
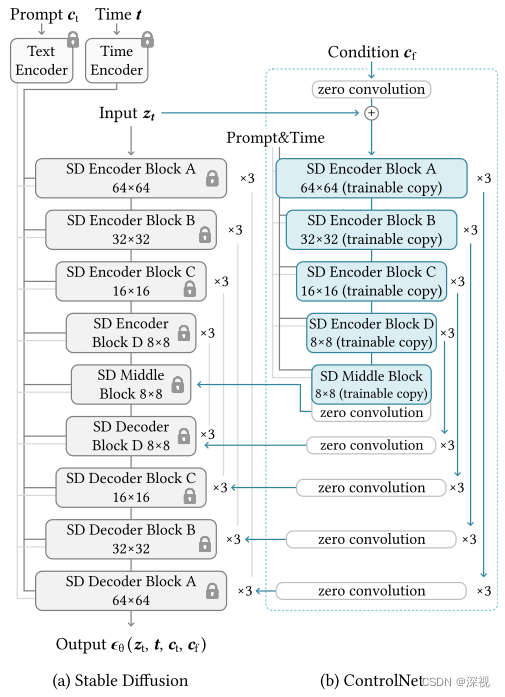
了解了单个模块中ControlNet是如何工作的,我们来看一下它是如何与StableDiffusion模型结合起来的,如上图所示SD模型是一个典型的UNet网络结构,由25个网络块构成,其中包含12个编码器、12个解码器和一个中间层。作者对12个编码器和一个中间层增加了ControlNet,即复制编码器块和中间层块的权重参数进行训练,并通过零卷积层与相应的解码器层进行连接。因为SD模型的前端有一个编码器将输入图像压缩至64*64尺寸的潜在特征,而输入的条件
c
f
c_f
cf通常与输入图像尺寸相同,因此也需要一个额外的小模型
E
\mathcal{E}
E将其尺寸统一为64 *64,
E
\mathcal{E}
E由四个卷积层构成在训练过程中与其他模块一起训练。
模型的损失函数还是采用了扩散模型的目标函数
L
=
E
z
0
,
t
,
c
t
,
c
f
,
ϵ
∼
N
(
0
,
1
)
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
,
c
t
,
c
f
)
)
∥
2
2
]
\left.\mathcal{L}=\mathbb{E}_{\boldsymbol{z}_{0}, \boldsymbol{t}, \boldsymbol{c}_{t}, \boldsymbol{c}_{\mathrm{f}}, \epsilon \sim \mathcal{N}(0,1)}\left[\| \epsilon-\epsilon_{\theta}\left(\boldsymbol{z}_{t}, \boldsymbol{t}, \boldsymbol{c}_{t}, \boldsymbol{c}_{\mathrm{f}}\right)\right) \|_{2}^{2}\right]
L=Ez0,t,ct,cf,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf))∥22]其中
c
f
\boldsymbol{c}_{\mathrm{f}}
cf表示输入的图像条件,
c
t
\boldsymbol{c}_{\mathrm{t}}
ct表示输入的文本条件。作者还提出了一种无分类器引导的分辨率加权技术(Classifier-free guidance resolution weighting,CFG-RW),将图像条件乘以不同的权重系数再作用于扩散模型的输出结果,权重系数根据每个网络块的分辨率来计算,
w
i
=
64
/
h
i
w_i=64/h_i
wi=64/hi,
h
i
h_i
hi为第
i
i
i个块的尺寸大小,如
h
1
=
8
,
h
2
=
16...
h_1=8,h_2=16...
h1=8,h2=16...
ControlNet在多种类型的图像条件下都取得了很好的生成效果,而且只需要10K左右的优化训练次数,目前ControlNet已经内置在SD软件中,并且提供了非常多类型的模型。最新的V1.1版本还增加了风格迁移、指令图像编辑等功能。